Jianping Lin (林建平)
CV / GitHub / Google Scholar / ORCID / Email: ljp105@mail.ustc.edu.cn, jianping_lin@sfu.ca

I am currently a PhD. candidate in the University of Science and Technology of China (USTC), supervised by Prof. Dong Liu and Prof. Houqiang Li. I am going to graduate from USTC in June 2021. I am also a visting research student in the Simon Fraser University (SFU), Canada, supervised by Prof. Jie Liang. I was working on deep learning-based video coding from October 2016. Currently, I focus on end-to-end learned video compression.
I received the B.S. degree in electronic engineering from the University of Science and Technology of China (USTC), Hefei, China, in 2016.
Publications and Manuscripts
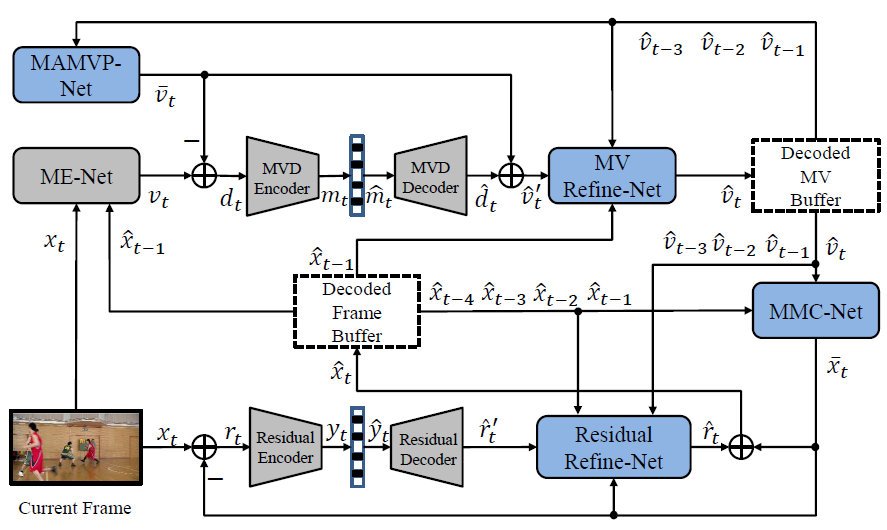
M-LVC: Multiple Frames Prediction for Learned Video Compression
Jianping Lin, Dong Liu, Houqiang Li, Feng WuIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
(Top Conference for Computer Vision)
[abstract] [paper] [arXiv] [code]
We propose an end-to-end learned video compression scheme for low-latency scenarios. Previous methods are limited in using the previous one frame as reference. Our method introduces the usage of the previous multiple frames as references. In our scheme, the motion vector (MV) field is calculated between the current frame and the previous one. With multiple reference frames and associated multiple MV fields, our designed network can generate more accurate prediction of the current frame, yielding less residual. Multiple reference frames also help generate MV prediction, which reduces the coding cost of MV field. We use two deep auto-encoders to compress the residual and the MV, respectively. To compensate for the compression error of the auto-encoders, we further design a MV refinement network and a residual refinement network, taking use of the multiple reference frames as well. All the modules in our scheme are jointly optimized through a single rate-distortion loss function. We use a step-by-step training strategy to optimize the entire scheme. Experimental results show that the proposed method outperforms the existing learned video compression methods for low-latency mode. Our method also performs better than H.265 in both PSNR and MS-SSIM. Our code and models are publicly available.
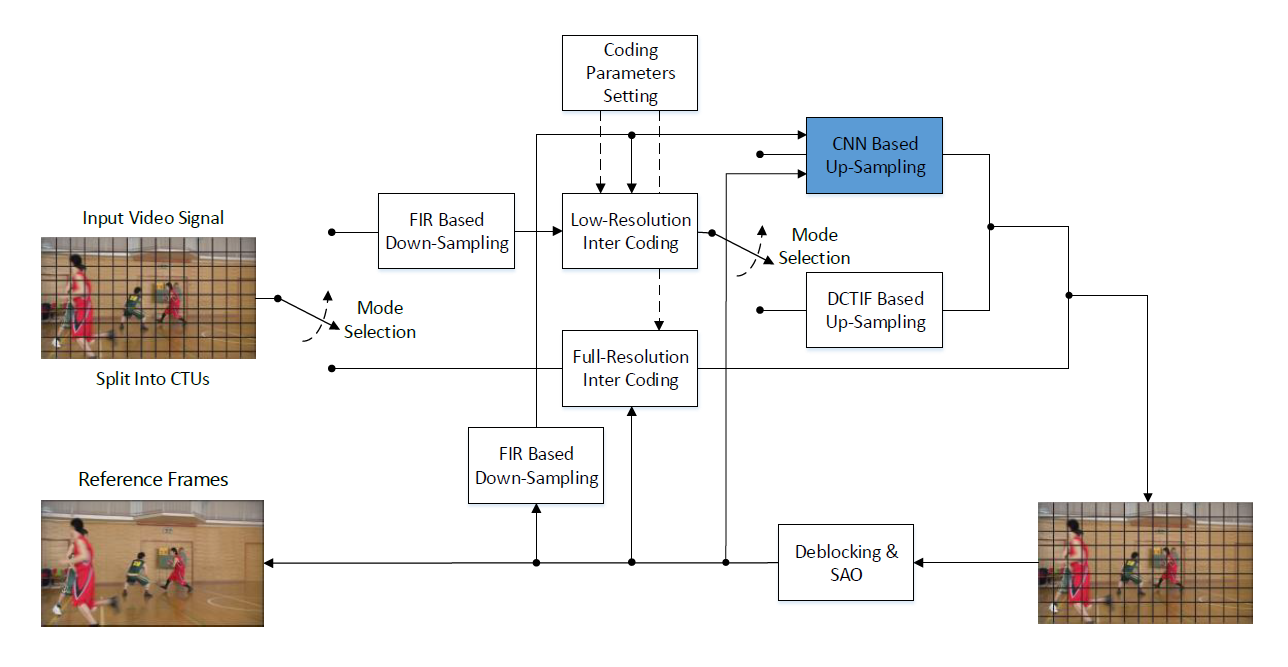
Convolutional Neural Network-Based Block Up-Sampling for HEVC
Jianping Lin, Dong Liu, Haitao Yang, Houqiang Li, Feng WuIEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2018
(Top Journal for Video Technology)
[abstract] [paper]
Recently, convolutional neural network (CNN)-based methods have achieved remarkable progress in image and video super-resolution, which inspires research on down-/up-sampling-based image and video coding using CNN. Instead of hand-crafted filters for up-sampling, trained CNN models are believed to be more capable of improving image quality, thus leading to coding gain. However, previous studies either concentrated on intra-frame coding or performed down- and up-sampling of entire frame. In this paper, we introduce block-level down- and up-sampling into inter-frame coding with the help of CNN. Specifically, each block in the P or B frame can either be compressed at the original resolution or down-sampled and compressed at low resolution and then, up-sampled by the trained CNN models. Such block-level adaptivity is flexible to cope with the spatially variant texture and motion characteristics. We further investigate how to enhance the capability of CNN-based up-sampling by utilizing reference frames and study how to train the CNN models by using encoded video sequences. We implement the proposed scheme onto the high efficiency video coding (HEVC) reference software and perform a comprehensive set of experiments to evaluate our methods. The experimental results show that our scheme achieves superior performance to the HEVC anchor, especially at low bit rates, leading to an average 3.8%, 2.6%, and 3.5% BD-rate reduction on the HEVC common test sequences under random-access, low-delay B, and low-delay P configurations, respectively. When tested on high-definition and ultrahigh-definition sequences, the average BD-rate exceeds 5%.
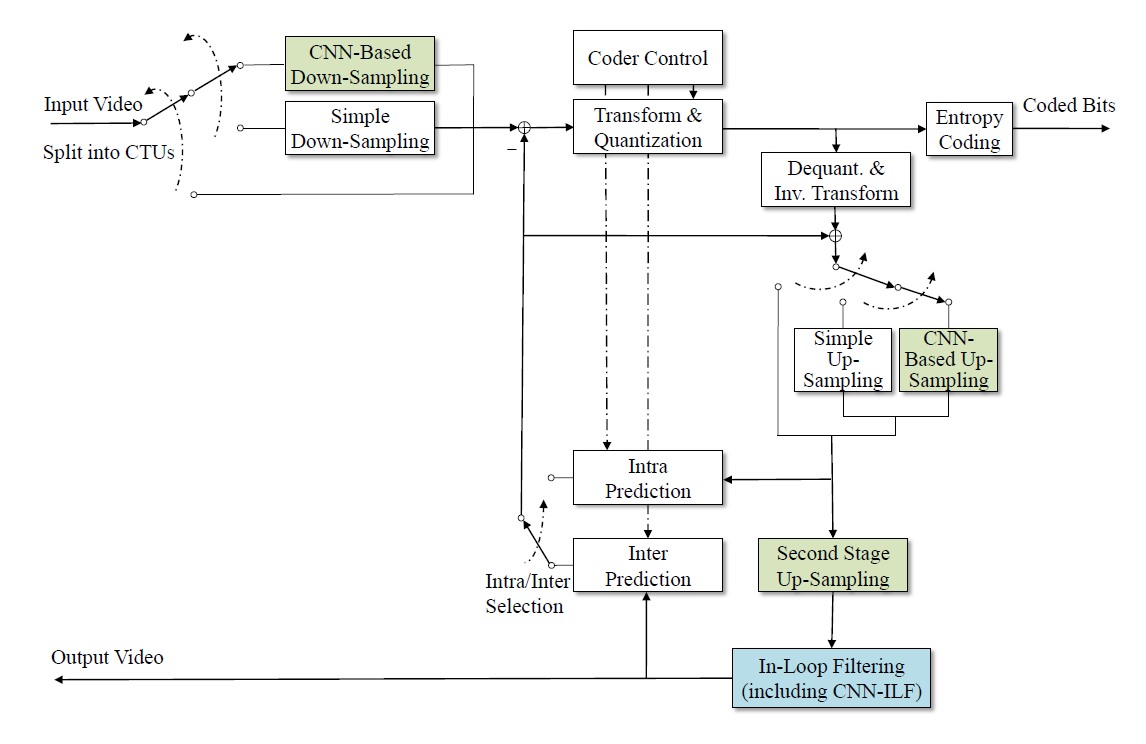
Deep Learning-Based Video Coding: A Review and A Case Study
Dong Liu, Yue Li, Jianping Lin, Houqiang Li, Feng WuACM Computing Surveys (CSUR), 2019
(Top Journal for Computing Surveys)
[abstract] [paper] [arXiv] [code]
The past decade has witnessed the great success of deep learning in many disciplines, especially in computer vision and image processing. However, deep learning-based video coding remains in its infancy. We review the representative works about using deep learning for image/video coding, an actively developing research area since 2015. We divide the related works into two categories: new coding schemes that are built primarily upon deep networks, and deep network-based coding tools that shall be used within traditional coding schemes. For deep schemes, pixel probability modeling and auto-encoder are the two approaches, that can be viewed as predictive coding and transform coding, respectively. For deep tools, there have been several techniques using deep learning to perform intra-picture prediction, inter-picture prediction, cross-channel prediction, probability distribution prediction, transform, post- or in-loop filtering, down- and up-sampling, as well as encoding optimizations. In the hope of advocating the research of deep learning-based video coding, we present a case study of our developed prototype video codec, Deep Learning Video Coding (DLVC). DLVC features two deep tools that are both based on convolutional neural network (CNN), namely CNN-based in-loop filter and CNN-based block adaptive resolution coding. The source code of DLVC has been released for future research.
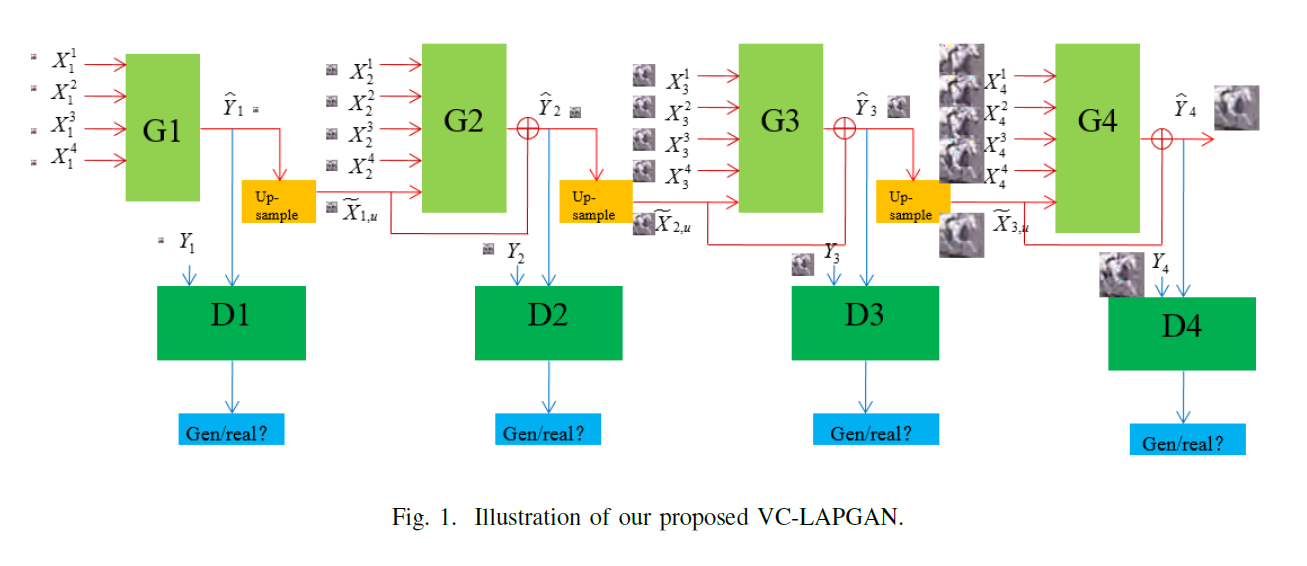
Generative Adversarial Network-Based Frame Extrapolation for Video Coding
Jianping Lin, Dong Liu, Houqiang Li, Feng WuIEEE Visual Communications and Image Processing (VCIP), 2018
[abstract] [paper]
Motion estimation and motion compensation are fundamental in video coding to remove the temporal redundancy between video frames. The current video coding schemes usually adopt block-based motion estimation and compensation using simple translational or affine motion models, which cannot efficiently characterize complex motions in natural video signal. In this paper, we propose a frame extrapolation method for motion estimation and compensation. Specifically, based on the several previous frames, our method directly extrapolates the current frame using a trained deep network model. The deep network we adopted is a redesigned Video Coding oriented LAplacian Pyramid of Generative Adversarial Networks (VC-LAPGAN). The extrapolated frame is then used as an additional reference frame. Experimental results show that the VC-LAPGAN is capable in estimating and compensating for complex motions, and extrapolating frames with high visual quality. Using the VC-LAPGAN, our method achieves on average 2.0% BD-rate reduction than High Efficiency Video Coding (HEVC) under low-delay P configuration.
Software Development
| The reference software of Deep Learning-Based Video Coding (DLVC) [bitahub] [github] [dockerhub] |
Professional Activities
| Reviewer for TMM |
My Presentations
| Introduction for Deep Learning-Based Video Coding [pdf] |
| Introduction for Learned Video Compression [pdf] |
| The lossy compression theory [pdf] |
Honours and Awards
| Scholarship under the State Scholarship Fund (CSC) | 2019 |
| National Encouragement Scholarship | 2015 |
| Outstanding Student Scholarship (Grade 2) of USTC | 2014 |
| Outstanding Student Scholarship (Grade 2) of Institudte of Modern Physics, China Academy of Sciences(IMPCAS) | 2013 |